BitFountain is a P2P system based on BitTorrent that leverages Digital Fountain erasure codes to encode and decode data.
What is the idea behind using erasure codes?
Let’s make a comparison with money. You need 100$ and you walk to the local bank.
You ask for 5$ banknotes but you want specific banknotes (you specify the “serial ID” for each of them).
It is complex, tedious, and requires time.
It is the same for BitTorrent: each file is composed of pieces, and each piece is identified by a number. You need to download each individual piece to reconstruct the original file.
The idea to use erasure codes is that you can generate infinite encoded blocks and to reconstruct the file, you need enough pieces to decode the original data.
Advantages
Its main advantage is a smaller average download completion time when the P2P network exceeds 100 nodes:
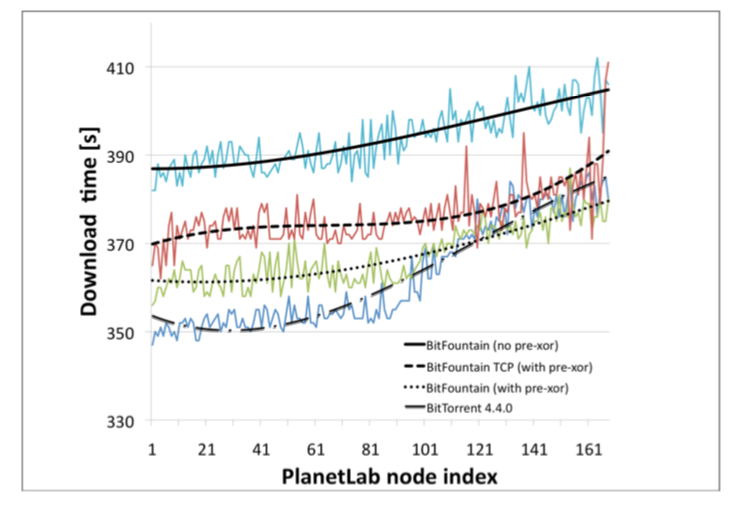
This remarkable result is achieved by encoding and decoding data on each of the peer constituting the P2P network. The Raptor erasure codes employed in BitFountain enrich each encoded block with redundant information that guarantees successful decoding on the receiver’s side provided that the receiver has downloaded enough encoded blocks to combine in order to reconstruct the original data.
This process resolves the “last missing piece” and improves the download performance even with packet losses (switch to UDP instead of TCP) and client failures.
BitFountain was presented as my M.Sc. thesis in December 2008. I continued my research experience in the “Network Research Lab” at the University of California, Los Angeles (UCLA).
After my initial research, the work has been continued and a technical paper about BitFountain was published.
Do you want to know what’s under the hood? Take a look at the BitFountain git repo on GitHub.